





Eon’s storage platform allows granular search and restore across clouds on customer databases. The platform ingests data from databases, virtual machines, and cloud object storage, transforming them into optimized Parquet blocks within a unified storage format designed for analytics and AI.
On top of this storage layer, Eon continuously builds a semantic index: a structured representation of every backed-up dataset’s tables, columns, inferred relationships, classifications, and metadata across clouds. This semantic index gives Eon contextual understanding of the data, not just how it is stored, but how it relates across systems and environments. Regardless of where the original data lives, users can search, query, and restore through a single, unified interface.
Eon doesn't just pass a raw schema to the LLM; it builds a semantic retrieval system that indexes our Parquet metadata and structural graph. By using our patented joinability algorithm, we can probabilistically detect join keys and relationships across petabytes of data without performing a full scan. When a query comes in, we use multi-level vector search together with agentic keyword search to retrieve only the relevant tables and columns, constructing a precise schema context window that fits efficiently into the model's prompt. An orchestration agent coordinates retrieval, context construction, validation, and SQL generation, routing each request through the appropriate tools to ensure accurate and explainable results.
That semantic layer is what makes natural-language search possible. Users ask questions like "How did my customer database change over time this month?" or "My production database was corrupted, can you retrieve the user records from the US from last week's backup?" and expect fast, accurate results.
Delivering this reliably in enterprise production environments introduces real technical constraints:
- Accuracy is critical: Our system needs to be able to handle a huge amount of different database schemas and create high-quality queries to run on top of them.
- Refusals matter as much as answers: When a question is ambiguous or references the wrong table, the model must refuse rather than guess. A confident but incorrect SQL response is worse than no response at all.
- Scale demands efficiency: Every query costs money and adds latency. Running every request through a large, expensive closed API doesn't scale.
Our initial iteration used a frontier model provider’s latest and most advanced model, which was a capable closed-source model that served as a strong baseline, and we wanted to see how we could compare it to other models.
The Solution: NVIDIA Nemotron and Model Cascading
We collaborated with NVIDIA and received early access to Nemotron 3 Super (model link), alongside the previously released Nemotron 3 Nano. Rather than simply swapping one model for another, we used a model cascading method that routes the right model for every query. We ran these on our inner benchmark dataset that we built and crafted. Because every query runs against the same well-defined Parquet schema, we can reliably classify query complexity and route it to the appropriate model tier.
What is model cascading?
Instead of sending every request to a single large model, we use a tiered approach: simpler, high-volume queries are handled by a lightweight, ultra-fast model (Nemotron 3 Nano), while complex, reasoning-heavy requests are cascaded to a more capable model (Nemotron 3 Super). This gives us the speed and cost efficiency of a small model for the majority of traffic, with the deep reasoning of a large model when it's truly needed.
Why Nemotron makes this possible
The Nemotron 3 family—Nano, Super, and Ultra—is purpose-built for this kind of tiered deployment. Under the hood, the architecture delivers a unique technical edge by combining three layer types:
- Mamba-2 Layers: Efficient state-space models (SSMs) that handle long sequences with constant memory usage, enabling massive context windows (up to 1M tokens) without the quadratic compute cost of traditional transformers.
- Hybrid MoE & LatentMoE: By routing tokens to only a fraction of the total experts, the model achieves the reasoning capacity of a much larger dense model while keeping inference fast and cheap. LatentMoE (in Super/Ultra) further optimizes this by projecting inputs into a lower-dimensional space, allowing for more experts and finer-grained specialization.
- Multi-Token Prediction (MTP) & NVFP4: These innovations boost throughput and reduce memory footprint, enabling powerful models to run efficiently at scale.
The result is a family of models that can reason like state-of-the-art models but run with the efficiency of lightweights, which was exactly what we needed for production NL-to-SQL, where both latency and accuracy matter.
How We Evaluated
We ran a structured evaluation over a broad set of test cases spanning simple, moderate, and complex queries, including cases where the model should refuse (wrong table, missing join, irrelevant question). We compared three strategies:
- Leading Frontier Model (baseline): Every query is sent to a leading LLM provider’s most advanced model.
- Routed (Nano + Super): Nemotron Nano for easier queries, Super for harder ones, to balance cost and quality.
We measured valid pass rate (correct SQL by both AST validation and semantic methods) and rejection accuracy (correct refusals when we expect them), along with relative cost and latency.
These were done using deterministic tests, alongside using an LLM as a judge for measuring the best responses.
The Results: Cascading Wins
Accuracy
Rejection accuracy: Nemotron 3 Super reached 94% rejection accuracy versus 88% for the baseline—a meaningful gain for safety and user trust. The cascading setup scored lower on refusals because Nemotron 3 Nano tends to answer rather than refuse on edge cases. This is a routing optimization problem, not a model limitation: by tuning our router to send refusal-sensitive queries to Super, we can close that gap without sacrificing cost or latency.
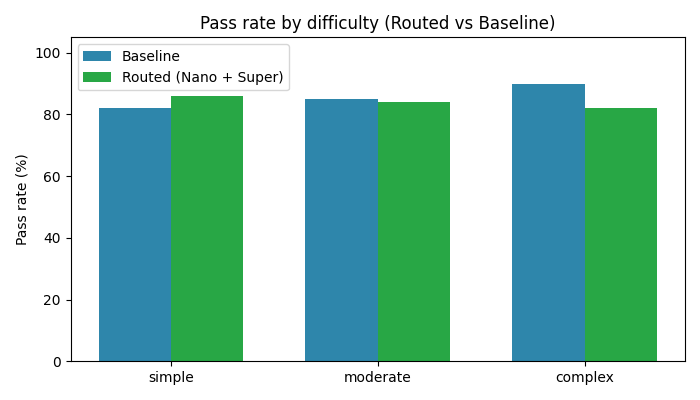
By difficulty: The figure below shows how cascading compares to the leading frontier model across difficulty tiers:
On easy difficulty cases, cascading outperformed the baseline (86% vs 82%). On moderate tasks, Cascading and the baseline were more or less tied. On the most complex queries—multi-join, deeply nested, or highly ambiguous—the baseline model maintained a lead (90% vs 82%). That said, complex queries represent a small fraction of production traffic, and this is exactly where fine-tuning Nemotron on our domain-specific schemas can close the gap over time.
Latency
Nemotron's architecture—Mamba-2 layers, sparse MoE routing, multi-token prediction—is designed for high-throughput, low-latency inference. The cascading strategy delivered a dramatic improvement:
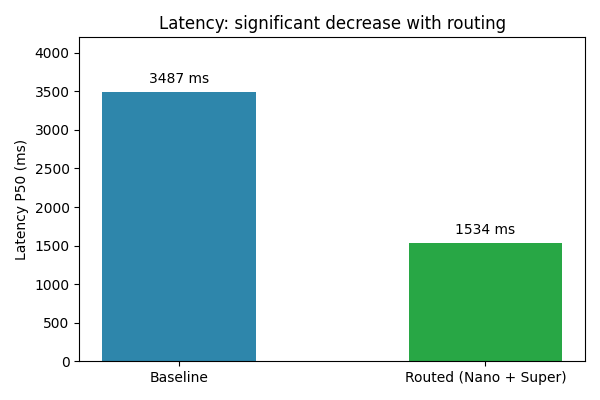
Cascading cut median latency by more than half: ~1,534ms vs the baseline’s ~3,487ms. This is because a large section of queries are handled by Nemotron 3 Nano, which responds in under a second. For a user waiting for search results, the difference between 1.5 seconds and 3.5 seconds is the difference between "instant" and "noticeable." The efficiency of Nemotron's hybrid architecture makes this possible without sacrificing the reasoning power we need for harder queries.
Cost
Nemotron 3 Super was already dramatically cheaper per query than the baseline model. The cascading strategy further reduced costs by routing most traffic to Nano. For a growing platform like ours, this changes the economics of running AI-powered search at scale.
Looking Ahead
Our evaluation validated our hypothesis: model cascading with the Nemotron family delivers accuracy comparable to a closed frontier model while dramatically reducing latency and cost. We're now focused on:
- Fine-tuning Nemotron on our proprietary schemas and refusal patterns to push accuracy even higher - another ability available by the open source Nemotron models.
- Expanding cascading to other AI-powered features across our backup platform.
NVIDIA's Nemotron family gave us the models to build on top of the semantic layer of petabytes of customer backups. Together, they've fundamentally shaped how we deploy AI in production—not by choosing the biggest model, but by building a pipeline that uses the right model for every query. Thanks to the NVIDIA team for the collaboration and early access to Nemotron 3 Super.
Eon is a member of the NVIDIA Inception program. Inception is a global program for AI startups that provides developer training and resources, valuable offers from NVIDIA and our partners, and preferred access to NVIDIA’s AI ecosystem.


