

.jpg)




Recovering cleanly from ransomware depends on one fact: knowing which recovery point is uncompromised, and when contamination began. Producing that fact is a detection problem, and Eon solves it from an unusual surface: the backup itself. Eon analyzes every snapshot for its logical contents, the files, blobs, rows, and schemas inside it, rather than scanning a disk image or a live host. The approach catches encryption inside managed-database backups, where there is no filesystem to scan, and it adds nothing to production.
The detection surface is the backup
A backup is usually treated as a passive artifact, a copy you hope you never need. Attackers do not treat it that way. In a Sophos survey of organizations hit by ransomware, 94% said attackers attempted to compromise their backups during the incident, and 57% of those attempts succeeded. Backups sit on the attack path as much as in the recovery plan, and real campaigns like Codefinger and Storm-0501 prove it.
Immutability is the usual answer, and it is necessary but not sufficient. Write-once-read-many (WORM) object locks block an attacker from deleting or overwriting a recovery point. They say nothing about whether the recovery point is clean. An immutable snapshot of an infected database is still infected. You can preserve a poisoned backup perfectly and restore it straight back into production.
Immutability answers one question: is the recovery point intact? Our engine answers a different one: is it clean, and if not, when did contamination begin? Answering that means reading what is inside each snapshot. And the moment you commit to reading inside the snapshot, the interesting design constraint appears: managed cloud databases and object stores never hand you a filesystem.
A managed RDS, Aurora, Postgres, MySQL, or MSSQL instance does not expose backup data as files on a disk you can scan. There is no volume to entropy-profile, no path to match a ransomware extension against. Conventional detection (entropy analysis, signature matching) operates at the filesystem or disk layer, so it has nothing to look at for these workloads. The result is a visibility gap in which ransomware can sit undetected inside a database backup for weeks, surfacing only after a contaminated restore. The rest of the engine follows from one move: analyzing the logical structure that exists instead of scanning files that don't.
System architecture
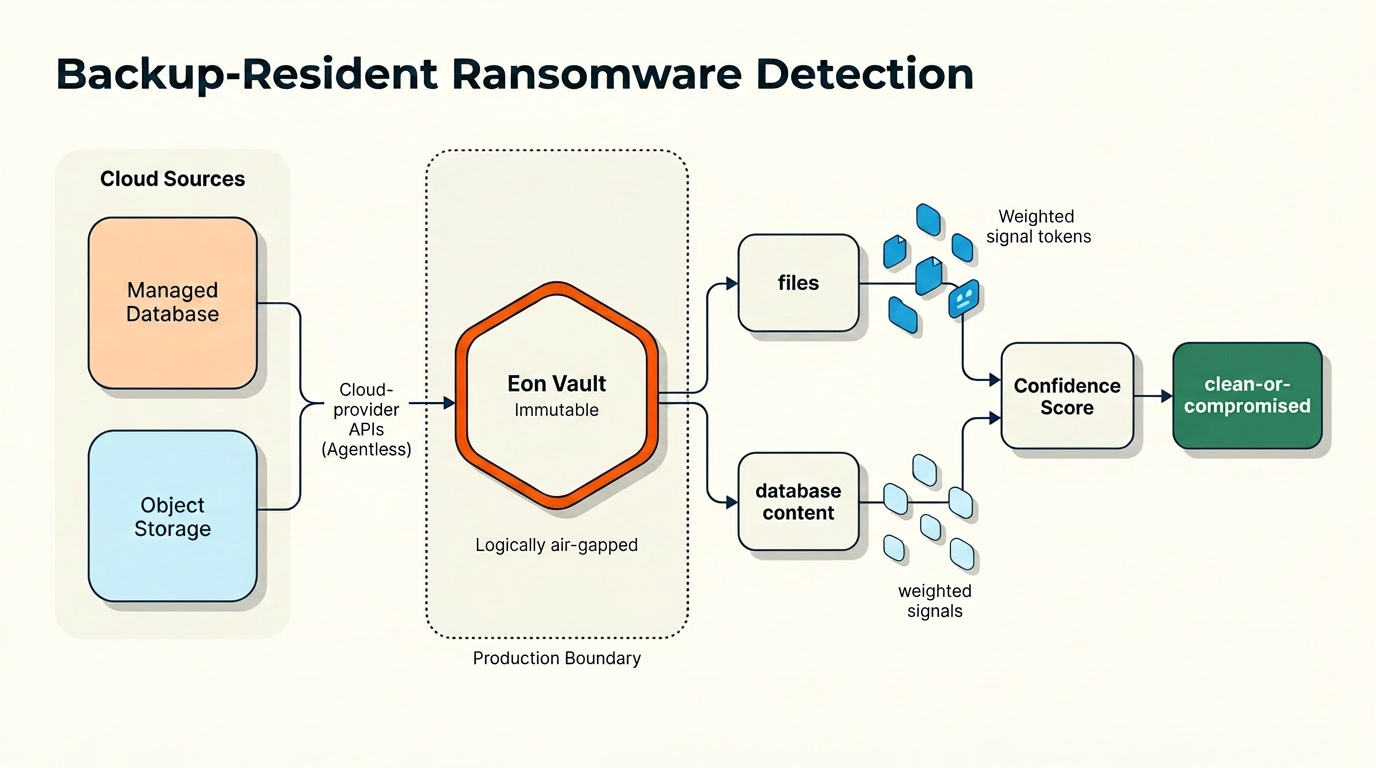
Snapshots land in a logically air-gapped vault
Eon integrates with cloud-provider APIs directly and stores every backup in a logically air-gapped (LAG) vault. Architecture enforces the air gap, not a configuration toggle: the vault sits outside production identity and access-management boundaries, so the same credentials, permissions, or compromised account that can reach production workloads cannot reach backup data. Combined with object-level WORM immutability and a tamper-evident audit trail, the design yields dual-layer protection, air-gapping plus immutability, so even an attacker holding production-level access cannot destroy the last clean copy. Eon also retains a protected resource's latest clean snapshot indefinitely, past normal retention expiry, so a clean recovery point always exists to fall back to.
Inside the vault, backups are held in queryable form: Eon exposes snapshot contents for SQL-style querying and exploration without performing a restore first. Queryability in place is the foundation everything else builds on. Because the data is queryable where it sits, the detection engine and the analyst-facing tools operate on the same representation, with no separate scanning copy and no production round-trip.
"Agentless" is an architectural property
Agentless is easy to read as a deployment convenience, but it is an architectural property. Our deployment is agentless and cloud-native, with no agents, appliances, or infrastructure changes on the protected systems. The security consequence: detection runs against data Eon already holds in the vault, off the production execution path. An agent-based detector adds software, and therefore attack surface, to every host it watches; a backup-resident detector adds none to the workload. There is a real trade-off: you observe the world at backup cadence rather than in real time.
Two pipelines, weighted evidence, a verdict
Detection runs at backup time and splits by what the data actually is. One pipeline handles files and blobs (VM backups and object storage), where there is byte content and, for VMs, a filesystem to reason about. A second pipeline handles databases, where the meaningful structure is tables, rows, schema, and value distributions rather than files. The two see different things because they are looking at different kinds of objects, and conflating them is exactly the mistake that leaves managed databases unmonitored.
Each pipeline emits signals: individual pieces of evidence, each with a weight. No single signal flags a backup on its own. Eon correlates multiple signals into a weighted confidence score and requires corroboration before declaring a backup compromised, which keeps the false-positive rate workable while preserving accuracy. For every flagged backup, the console surfaces exactly what changed, which signals fired, and the resulting confidence score: the evidence an operator needs to make a recovery decision.
The sections that follow take the two pipelines in turn, beginning with the database pipeline, because backup-resident detection does something there that nothing else structurally can.
Detecting encryption inside a database backup
The premise is uncomfortable at first: detect encryption without ever seeing a file. You cannot measure the entropy of a managed database's backup, because the cloud provider never exposes it as bytes on a volume. What you can do is read the logical contents of the backup (the tables, the rows, the schema, the distribution of values in each column) and ask whether they have been deformed in the specific ways encryption deforms data. Eon is the first cloud-native platform to analyze the logical contents of database backups rather than the storage files wrapping them, across PostgreSQL, MySQL, MSSQL, RDS, DynamoDB, and others.
Several structural signals become available once you are reading logical content:
- Schema diffing. Comparing the schema of consecutive snapshots surfaces dropped or altered tables and columns, modifications no application change explains.
- Row- and table-count behavior. Sudden, unexplained collapses in row or table counts can indicate destructive deletion or wholesale rewriting of the data.
- Embedded ransom-note indicators. Ransomware frequently writes its demand directly into the dataset: a new row, a new low-cardinality column, a repeated string standing in for values that used to be diverse. A ransom note in a database does not look like a README.txt on disk; it looks like a column whose values are suddenly all identical contact instructions.
The centerpiece is cardinality analysis.
Cardinality is the number of distinct values in a column. A status column with a handful of values (active, pending, closed) is low-cardinality: a few distinct values repeated across millions of rows. A user_id or email column is high-cardinality: nearly every value is unique. The distribution is a stable property of a healthy table; it reflects the meaning of the column and barely moves day to day.
Encryption destroys that property in a characteristic way. When ransomware encrypts a column's values, every repeated plaintext becomes a distinct ciphertext. The low-cardinality status column, three values yesterday, becomes a column of all-unique, high-entropy strings today. The collapse of repetition into uniqueness is observable purely from the value distribution, with no access to a single byte of the underlying storage file. It is the database-shaped fingerprint of the same uniformity that entropy analysis exploits on files.
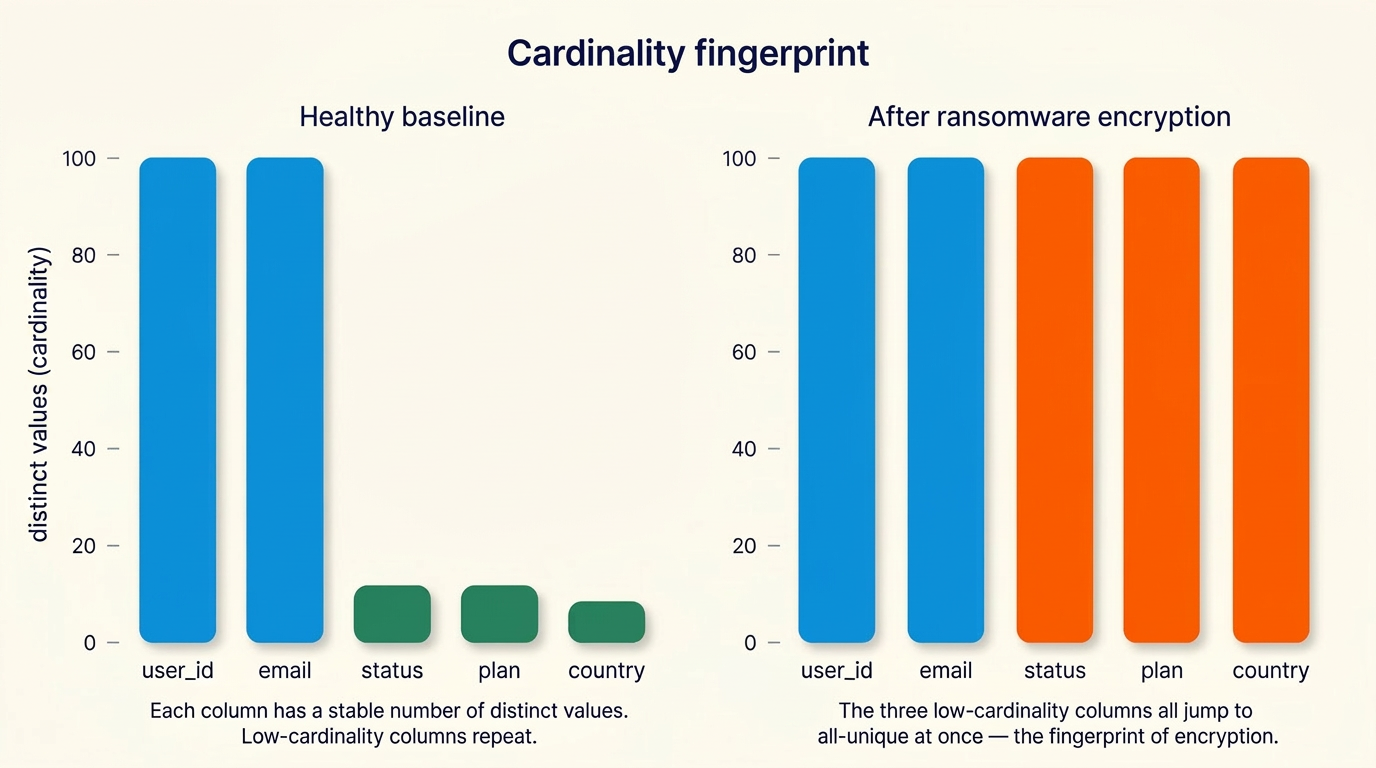
The naive version of the signal false-positives immediately. A legitimate bulk migration (re-keying a column, hashing a field for privacy, importing a new high-cardinality identifier) can also turn a low-cardinality column into a high-cardinality one. If "low-cardinality column became all-unique" were sufficient to flag ransomware, every routine schema migration would generate a false alert.
Breadth is the discriminator. A legitimate migration is targeted: it touches the one column the engineer meant to change. Encryption is indiscriminate: it forces many columns across a table (often across many tables) from low to high cardinality simultaneously and uniformly. A single column's distribution shifting is routine. The same shift happening across most of a table's low-cardinality columns at once, in lockstep, is not something benign workloads do. The engine reasons over the pattern across columns rather than any one column's value, which separates a destructive encryption event from a planned bulk change. The design point is the joint behavior; the specific thresholds and weights behind it are implementation detail.
The same logical visibility lets Eon, after a verdict, scope recovery to the affected tables or records instead of the whole database.
The file and blob pipeline
For VM backups and object storage, there is byte content, so the pipeline can use the classical signals, but the useful versions of them are the corroborated ones. For file workloads, detection covers entropy changes, file and block change rates, system-file changes, ransomware-extension patterns, known malware signatures, and embedded ransom notes, plus mass-deletion, abnormal-access, and object-integrity anomaly detection for object storage. Each of these has a naive form that false-positives, and the engineering is mostly in avoiding that.
- Entropy as a delta rather than an absolute. Encrypted data approaches maximal, uniform byte entropy; uniformity is the defining property that entropy estimation exploits to separate encrypted files from clean ones. But absolute entropy is a bad detector on its own: already-compressed or already-encrypted formats (ZIP archives, JPEGs, media, anything gzipped) also read as high-entropy, and a backup full of them would light up constantly. The signal that carries weight is the change in entropy for a given file between snapshots: a document, spreadsheet, or config file that was structured and low-entropy yesterday and is uniformly high-entropy today. The baseline is the file's own history rather than a global threshold.
- Ransomware extensions intersected with entropy. A known ransomware extension on a filename is suggestive but trivially spoofable, and plenty of legitimate files carry odd extensions. The high-confidence signal is the intersection: files whose extensions match ransomware naming conventions and whose contents have jumped to high entropy. Either alone is weak; together they corroborate.
- Balanced add/delete within a directory. Ransomware that encrypts in place often writes a new encrypted file and removes the original, producing a directory where additions and deletions are tightly balanced and the survivors are high-entropy. A naive "mass file deletion" rule would fire on a routine cleanup; pairing the deletions with matching high-entropy additions in the same directory is what distinguishes encryption from housekeeping.
- S3 re-encryption (SSE-C / KMS). File scanners cannot model this case at all. In the Codefinger campaign, attackers with valid stolen AWS credentials used CopyObject with server-side encryption using customer-provided keys (SSE-C) to overwrite objects with a key only they hold; AWS cannot recover the data because it never stores the SSE-C key. AWS has confirmed the campaign abused valid credentials rather than a service vulnerability, and that telling malicious use apart from legitimate use at the control plane is hard. At the API layer the operation looks like ordinary, authorized activity, which is precisely why a control-plane detector struggles. From the backup content side, the effect is observable: objects that were readable become unreadable, their integrity no longer verifies, encryption state changes en masse. Coverage here comes from the object-integrity-anomaly and abnormal-access signals rather than any single bespoke detector.
- Mass-deletion detection. Object-store ransomware increasingly destroys rather than encrypts. Detecting a deletion spike is straightforward; the engineering, again, is in avoiding false alerts on a legitimate lifecycle expiry or a planned bucket teardown, which is why deletion volume is weighted alongside access-pattern and integrity context rather than treated as a verdict by itself.
The throughline across both pipelines: every signal that works in production is the corroborated, delta-aware version of a signal that would be useless on its own.
Forecasting: learning each resource's normal rhythm
Static thresholds are the wrong tool for the residual problem, because "normal" is not a global constant. It is per-resource. A nightly ETL job rewrites half a warehouse on schedule. A logging system rotates and compresses files continuously. A build pipeline emits high-entropy compiled binaries every commit. Each of these, judged against a fixed threshold, looks like an attack. Judged against the resource's own history, none of them do.
So before the engine calls an anomaly, a behavioral model learns each resource's normal rhythm (its baseline change rate, its seasonality, its backup cadence) over a window of recent history, and judges new snapshots against the learned baseline rather than a universal cutoff. We call this behavioral anomaly tracking and advanced pattern-change detection for cloud databases; the design rationale is that a deviation only means something relative to what is normal for that resource. A warehouse rewritten every night has a baseline that includes nightly rewrites; the same rewrite on a resource that has been static for weeks is anomalous. The baseline needs history to exist.
The multi-signal design is what recovers precision here. The individual signal detectors are deliberately permissive: each is tuned to surface anything that could be an attack, accepting that any one of them, alone, will fire on benign activity. Precision comes from correlation rather than from making each detector stricter: Eon requires multiple weighted signals to agree before a backup is flagged, so a lone high-entropy delta or a single cardinality shift does not produce a verdict on its own. The principle is to collect broadly and conclude conservatively: high sensitivity in the detectors, precision in the weighted confidence step that combines them.
The natural-language interface: investigation and response over MCP
Because backups are queryable in place, the same engine that produces verdicts is something an analyst can interrogate directly. Eon's AI Agent lets teams query backup and archive data in natural language, with no restores or ETL pipelines and no schema expertise required, running entirely against the immutable, air-gapped vault rather than production. The agent discovers relevant tables across regions, accounts, and clouds, infers relationships even where foreign keys and documentation are missing, generates dialect-accurate SQL with built-in validation safeguards, and reads Eon's OpenAPI specification at run time to discover platform capabilities.
Teams reach it through a built-in conversational interface or programmatically over Model Context Protocol (MCP) and agent-to-agent (A2A) integrations with environments like Claude Code, Gemini, and Codex. Detection output becomes the beginning of a workflow rather than the end of one. Concretely:
- "Did CVE-XXXX touch any asset in our estate, and which recovery points predate it?" Cross-resource, cross-snapshot analysis with automatic join detection, scoped to the vault.
- "Recover only the clean data from before the encryption event, and give me the runbook." Recovery-point validation before restore, paired with granular recovery.
- "Which databases show cardinality anomalies this week, and are any of them in production?" The detection engine's own findings, filtered and joined against posture data, in plain English.
One property makes the agent safe to expose: every action it takes runs under the authenticated user's own identity, so existing access controls hold end-to-end. Rather than running as a privileged service account that widens the blast radius, the agent stays bound to the permissions of the person asking. The same engine that detects becomes something you can question and act through, without standing up a parallel access path.
Trade-offs and limitations
Backup-resident detection is a deliberate set of trade-offs.
- You observe at backup cadence rather than in real time. Detection runs when a snapshot is taken, so an attack becomes visible at the next backup rather than at the keystroke. Backup-resident detection is a recovery-integrity and clean-restore-point layer, strongest when paired with real-time production controls rather than replacing them.
- Behavioral baselines do not exist on day one. A baseline measured against a resource's own history needs that history to accumulate. Freshly onboarded resources lean on the structural and static signals (schema diffs, cardinality, entropy deltas against the first snapshots) until the behavioral model has enough to work with.
- Corroboration bounds sensitivity as well as false positives. Requiring multiple weighted signals before flagging keeps the engine usable, but it also means a sufficiently slow, narrow, low-volume manipulation that mimics legitimate change can stay under the bar. Precision and recall trade against each other; the design captures recall broadly in the detectors and pays for precision at the correlation step, but the bound is real.
From verdict to surgical recovery
Detection is only useful if it changes what recovery looks like, and the engine's logical visibility is exactly what makes recovery granular. A timeline view shows when a resource's backups began showing signs of compromise, so operators identify the last known-clean restore point instead of guessing from timestamps. A clean-image selector picks the most recent uncompromised version ahead of restore, and isolated restore staging validates it in a sandbox before promoting to production.
Most importantly, because Eon knows what changed (which objects, which tables, which records), it can restore only the affected data rather than rolling back an entire environment. You recover specific files, directories, or objects, or individual database tables and records, from a clean point. Legacy tools that treat a snapshot as an indivisible unit force a full-environment rollback to recover a single object, which lengthens recovery and risks dragging contaminated data back in with the clean. Granularity also shows up in the numbers: NETGEAR cut recovery of a 10TB SQL Server database from 24 hours to under 3 after moving to Eon. Reading inside the backup turns recovery from a blunt rollback into a surgical operation.
If you run multi-cloud production on managed databases and object storage, the fastest way to evaluate the engine is a scoped pilot against your own estate. Request a consultation.


